
CloudNet 가시다님이 진행하는 Kubernetes Advanced Network Study 5주차 정리입니다.

3. MetalLB-BGP 모드
MetalLB에 BGP 모드는 Kubernetes 클러스터에서 서비스(Service)의 External IP를 외부 네트워크에 광고하기 위한 방식 중 하나입니다. 특히, 온프레미스 환경에서 BGP(Border Gateway Protocol) 라우팅 프로토콜을 사용하여 외부 라우터와 통신하며, 서비스의 IP를 더욱 안정적이고 확장성 있게 관리할 수 있도록 해줍니다.
- 안정적인 서비스 IP 관리 : BGP 프로토콜의 특성상 네트워크 토폴로지 변화에 강건하며, 다중 경로를 지원하여 장애 발생 시에도 서비스 가용성을 유지할 수 있습니다
- 확장성 : BGP는 대규모 네트워크 환경에서도 효율적으로 작동하며, 서비스가 증가하더라도 유연하게 대처할 수 있습니다
- 세밀한 제어 : BGP 커뮤니티, AS 패스, local preference 등 다양한 BGP 속성을 활용하여 트래픽 엔지니어링이 가능
- 표준 프로토콜 : BGP는 널리 사용되는 표준 프로토콜이므로, 기존 네트워크 환경과의 통합이 용이
MetalLB-BGP 모드의 작동 원리
1. MetalLB 설치 : Kubernetes 클러스터에 MetalLB를 설치하고 BGP 모드를 활성화합니다
2. Speaker Pod 생성 : MetalLB는 각 노드에 Speaker Pod를 생성하며, 이 Pod들이 서비스의 External IP를 BGP 광고를 통해 외부 네트워크에 알립니다
3. BGP Peer 구성 : Speaker Pod와 외부 라우터 간에 BGP Peer 관계를 설정합니다
4. 라우팅 정보 교환 : Speaker Pod는 서비스의 External IP를 포함한 라우팅 정보를 외부 라우터에 광고하고, 외부 라우터는 이 정보를 기반으로 라우팅 테이블을 업데이트 합니다
5. 트래픽 분산 : 외부에서 서비스의 External IP로 들어오는 트래픽은 외부 라우터에 의해 해당 서비스가 위치한 노드로 전달되고, Kubernetes Service의 로드 밸런싱 기능을 통해 실제 Pod로 분산됩니다
3.1 MetalLB - BGP 모드 설정
▶ MetalLB ConfigMap 생성
cat <<EOF | kubectl replace --force -f -
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
peers:
- peer-address: 192.168.10.254
peer-asn: 64513
my-asn: 64512
address-pools:
- name: default
protocol: bgp
avoid-buggy-ips: true
addresses:
- 172.20.1.0/24
EOF
▶ 리눅스 라우터에 BGP 설정(예시)
router bgp 64513
bgp router-id 192.168.10.254
maximum-paths 4
network 10.1.1.0/24
neighbor 192.168.10.10 remote-as 64512
neighbor 192.168.10.101 remote-as 64512
neighbor 192.168.10.102 remote-as 64512
...: neighbor -> worker node
3.2 서비스 생성 및 확인
▶ BGP 정보 확인(k8s-rtr) : 서비스(EX-IP)들을 32bit IP를 전달 받음 -> 축약 대역 전파 설정 가능 => 다만, 노드들은 상대측 BGP 네트워크 정보를 받지 않는다
: 서비스(EX-IP) 3개의 각각 IP에 대해서 k8s 노드로 ECMP 라우팅 정보가 업데이트!
ip -c route | grep 172.20. -A3
172.20.1.1 proto zebra metric 20
nexthop via 192.168.10.10 dev enp0s8 weight 1
nexthop via 192.168.10.101 dev enp0s8 weight 1
nexthop via 192.168.10.102 dev enp0s8 weight 1
172.20.1.2 proto zebra metric 20
nexthop via 192.168.10.10 dev enp0s8 weight 1
nexthop via 192.168.10.101 dev enp0s8 weight 1
nexthop via 192.168.10.102 dev enp0s8 weight 1
172.20.1.3 proto zebra metric 20
nexthop via 192.168.10.10 dev enp0s8 weight 1
nexthop via 192.168.10.101 dev enp0s8 weight 1
nexthop via 192.168.10.102 dev enp0s8 weight 1
* BGP 상세 정보 확인
# show bgp ipv4 unicast summary
# show ip bgp
# show running-config
3.3 서비스 접속 테스트
▶ 클라이언트(k8s-pc) -> 서비스(External-IP) 접속 테스트
ip -c route | grep zebra
10.1.1.0/24 via 192.168.20.254 dev enp0s8 proto zebra metric 20
172.20.1.1 via 192.168.20.254 dev enp0s8 proto zebra metric 20
172.20.1.2 via 192.168.20.254 dev enp0s8 proto zebra metric 20
172.20.1.3 via 192.168.20.254 dev enp0s8 proto zebra metric 20- 클라이언트 -> 서비스(External-IP) 접속 시 : 라우터 ECMP 분산 접속으로 노드 인입 후 Service에 매칭된 iptables rules에 따라 랜덤 부하 분산되어(SNAT) 파드로 접속!
3.4 externalTrafficPolicy : Local 테스트
▶ 리눅스 라우터에서 BGP 정보 확인
[k8s-rtr] 파드가 있는 노드만 nexthop 올라옴 (현재 마스터 노드에 파드가 없는 상태)
ip -c route
172.20.1.1 proto zebra metric 20
nexthop via 192.168.100.102 dev enp0s8 weight 1
nexthop via 192.168.100.101 dev enp0s8 weight 1
172.20.1.2 proto zebra metric 20
nexthop via 192.168.100.101 dev enp0s8 weight 1
nexthop via 192.168.100.102 dev enp0s8 weight 1
172.20.1.3 proto zebra metric 20
nexthop via 192.168.100.102 dev enp0s8 weight 1
nexthop via 192.168.100.101 dev enp0s8 weight 1
...
- 클라이언트 -> 서비스(External-IP) 접속 : 라우터 ECMP 분산 접속, 클라이언트의 IP가 보존!
- MetalLB 사용 시 가장 권장하는 방법은 BGP 모드에 externalTrafficPolicy : Local 설정을 하는 것!
- 네트워크팀과 협조하여 최적의 라우팅 장애 시 빠른 절체, 그리고 클라이언트 IP 보존 등의 기능 제공 가능
- 추가 고려사항은 한 노드에 목적지 파드가 다수일 경우 부하분산의 불균형이 발생할 수 있으니, pod anti-affinity로 최대한 노드별로 목적지 파드를 균등하게 배치 필요!
3.5 Failover 테스트
▶ 노드 reboot 시 BGP update에 Withdrawn Routes 정보로 전달하게 되고, 라우터가 받게 되면 해당 네트워크 정보를 바로 삭제하여 정상적인 노드로 트래픽 인입 -> 거의 무중단
- 다만, 위 경우 정상적인 절차의 종료로 BGP 역시 정상 종료 절차로 인해 빠른 절체가 된것이다
- 다양한 장애 발생 상황이 있고, k8s 역시 노드 장애 판단 시간, 파드 자체의 장애 판단 시간과 대응 등 복합적인 절차 상황을 종합하여 테스트 필요
- BGP with BFD가 MetalLB에서는 미지원 상태.
4. 기타
4.1 ExternalIP 서비스
▶ ExternalIP 서비스 소개
- ExternalIP 서비스는 특정 노드IP(포트)로 인입한 트래픽을 컨테이너로 보내(ClusterIP를 사용), 외부에서 접속할 수 있게 합니다
=> NodePort와 거의 유사하니, 특별한 이유가 없으면 NodePort(ExternalTrafficPolicy 등 옵션 사용 가능)를 사용! - ExternalIP는 노드 1개 혹은 일부 노드들을 지정할 수 있다
- ExternalTrafficPolicy 정책을 사용할 수 없다 -> 즉 외부에서 ExternalIP로 접근 시 무조건 Node의 IP로 DNAT 되어서 Client IP 수집할 수 없다
| 설정 항목 | 설명 |
| spec.externalIPs | 노드 IP 주소(ExternalIP) |
| spec.ports[].port | ExternalIP와 ClusterIP에서 수신할 포트 번호 |
| spec.ports[].targetPort | 목적지 컨테이너 포트 번호 |
4.3-1 On-prems Service(LoadBalancer Type) SW
- OpenELB (구 PorterLB) : ARP와 BGP 모드 제공, BGP는 GoBGP 사용
- Kube-vip : 원래 k8s Control HA 기능 제공에서 만들다가 LB 쪽도 유사해서 기능 제공, ARP와 BGP모드 제공, BGP는 GoBGP 사용
- PureLB : MetalLB Fork, ARP와 BGP 모드 제공, BGP는 Bird 사용
IPVS Proxy 모드
▶ 참고 링크
https://github.com/kubernetes/kubernetes/blob/master/pkg/proxy/ipvs/README.md
kubernetes/pkg/proxy/ipvs/README.md at master · kubernetes/kubernetes
Production-Grade Container Scheduling and Management - kubernetes/kubernetes
github.com
https://kubernetes.io/docs/reference/networking/virtual-ips/#proxy-mode-ipvs
Virtual IPs and Service Proxies
Every node in a Kubernetes cluster runs a kube-proxy (unless you have deployed your own alternative component in place of kube-proxy). The kube-proxy component is responsible for implementing a virtual IP mechanism for Services of type other than ExternalN
kubernetes.io
▶ 실습 환경 구성


: strictARP : true는 ARP 패킷을 보다 엄격하게 처리하겠다는 설정이다.
: IPVS 모드에서 strict ARP가 활성화되면, 노드의 인터페이스는 자신에게 할당된 IP 주소에 대해서만 ARP 응답을 보내게 됩니다. 이는 IPVS로 로드밸런싱 할 때 ARP 패킷이 잘못된 인터페이스로 전달되는 문제를 방지합니다.
이 설정은 특히 클러스터 내에서 여러 노드가 동일한 IP를 갖는 VIP(Virtual IP)를 사용하는 경우 중요합니다.

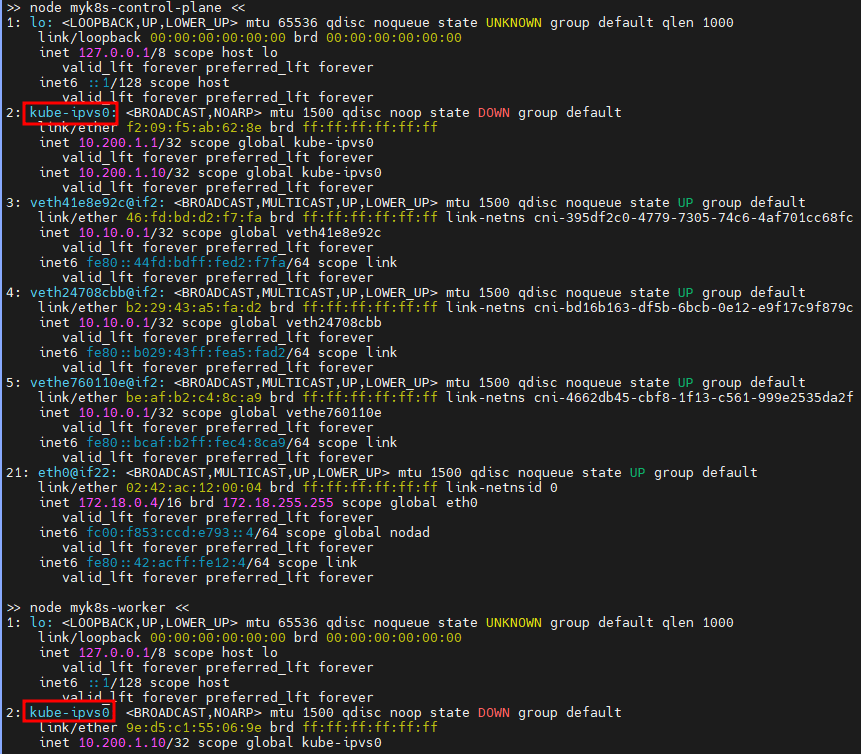
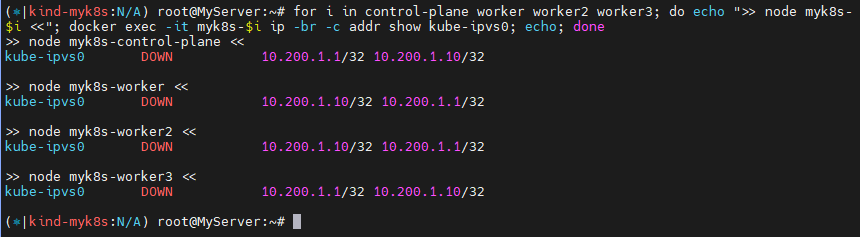


: Service IP(VIP) 처리를 ipvs에서 담당 -> 이를 통해 iptables에 체인/정책이 상당 수준 줄어듬

IPVS 프록시 모드 (kernal IPVS, iptables APIS -> netfilter subsystem)
- In ipvs mode, kube-proxy uses the kernel IPVS and iptables APIs to create rules to redirect traffic from Service IPs to endpoint IPs.
- The IPVS proxy mode is based on netfilter hook function that is similar to iptabels mode, but uses a hash tables as the underlying data structrue and works in the kernel space. That means kube-proxy in IPVS mode redirects traffic with lower latency than kube-proxy in iptables mode, with much better performance when synchronizing proxy rules. Compared to the iptables proxy mode, IPVS mode also supports a higher throughput of network traffic.
- IPVS Mode는 Linux Kernel에서 제공하는 L4 Load Balancer인 IPVS가 Service Proxy 역할을 수행하는 Mode 이다.
- Packet Load Balancing 수행 시 IPVS가 iptabels 보다 높은 성능을 보이기 때문에 IPVS mode는 iptables Mode 보다 높은 성능을 보여준다
- IPVS 프록시 모드는 itpables 모드와 유사한 넷필터 후크 기능을 기반으로 하지만, 해시 테이블을 기본 데이터 구조로 사용하고 커널 스페이스에서 동작한다
- 이는 IPVS 모드의 kube-proxy는 iptables 모드의 kbue-proxy보다 지연 시간이 짧은 트래픽을 리다이렉션하고, 프록시 규칙을 동기화할 때 성능이 훨씬 향상됨을 의미한다
- 다른 프록시 모드와 비교했을 때, IPVS 모드는 높은 네트워크 트래픽 처리량도 지원한다.
IPVS 부하 분산 : rr, wrr, lc, wlc, lblc, lblcr, sh, dh, sed, nq
- rr (Round Robin) : Traffic is equally distributed amongst the backing servers.
- wrr (Weighted Round Robin) : Traffic is routed to the backing servers based on the weights of the servers. Servers with higher weights receive new connections and get more requests than servers with lower weights.
- lc ( Least Connection) : More traffic is assigned to servers with fewer active connections.
- wlc (Weighted Least Connection) : More traffic is routed to servers with fewer connections relative to their weights, that is, connections divided by weight.
- lblc (Locality based Least Connection) : Traffic for the same IP address is sent to the same backing server if the server is not overloaded and available; otherwise the traffic is sent to servers with fewer connections, and keep it for future assignment.
- lblcr (Locality Based Least Connection with Replication) : Traffic for the same IP address is sent to the server with least connections. If all the backing servers are overloded, it picks up one with fewer connections and add it to the target set. If the target set has not changed for the specified time, the most loaded server is removed from the set, in order to avoid high degree of replication.
- sh(Source Hashing) : Traffic is sent to a backing server by looking up a statically assigned hash table based on the source Ip addresses.
- dh (Destination Hashing) : Traffic is sent to a backing server by looking up a statically assigned hash table based on tehir destination addresses.
- sed (Shortest Expected Delay) : Traffic forwared to a backing server with the shortest expected delay. The expected delay is (C+1) / U if sent to a server, where C is the number of connections on the server and U is the fixed service rate (weight) of the server.
- nq (Never Queue) : Traffic is sent to an idle server if there is one, instead of waiting for a fast one; if all servers are busy, the algorithm falls back to the sed behavior.
♣ To run kube-proxy in IPVS mode, you mut make IPVS available ont he node before starting kube-proxy. When kube-proxy starts in IPVS proxy mode, it verifies whether IPVS kernel modules are available. If the IPVS kernel modules are not detected, then kbue-proxy exits with an error.
▶ IPVS 소개 (정보 수집)
- IPVS는 리눅스 커널에서 동작하는 소프트웨어 로드밸런서이다. 백엔드(플랫폼)으로 Netfilter를 사용하며, TCP/UDP 요청을 처리 할 수 있다.
- iptales의 rule 기반 처리의 성능 한계와 분산 알고리즘이 없어서, 최근에는 대체로 IPVS를 사용한다
♣ IPVS(IP Virtual Server) implements transport-layer load balancing, usually called Layer 4 LAN switching, as part of the Linux kernel. It's configured via the user-space utility ipvsadm(8) tool.
IPVS is incorporated into the Linux Virtual Server(LVS), where it runs on a host and acts as a load balancer in front of a cluster of real servers. IPVS can direct requests for TCP and UDP based services to the real servers, and make services of the real servers appear as virtual services on a single IP address. IPVS is build on top of the Netfilter.
Netfilter Hook Function : 6개의 Netfilter Hook Function을 사용 -> Local Hook 사용 이유는 IPVS Dummy Interface 사용하기 때문

부하 분산 스케줄링 : kbue-proxy 파라미터에 설정 적용 -ipvs-scheduler

IPSET
- iptables로 5000건 이상의 룰셋이 등록 되었을 때 시스템의 성능이 급격하게 떨어지는 반면 룰을 줄일 수 있는 방법 중 'IP들의 집합'으로 관리 => IPSET
- 아래는 ipvs proxy mode 사용 시 설정되는 기본 ipset 내용

▶ IPVS 정보 확인



: strictARP - 링크 설정(유사한) 이유
: --ipvs-strict-arp : Enable strict ARP by setting arp_ignore to 1 and arp_announce to 2
: arp_ignore : ARP request 를 받았을 때 응답 여부 - 0(ARP 요청 도착 시, any Interface 있으면 응답), 1(ARP 요청을 받은 Interface가 해당 IP일때만 응답)
: arp_announce : ARP request 를 보낼 때 'ARP Sender IP 주소'에 지정 값 - 0(sender IP로 시스템의 any IP 가능), 2(sender IP로 실제 전송하는 Interface 에 IP를 사용)




: 인입 시 3곳의 목적지로 라운드로빈로 부하분산하여 전달됨 확인 : 모든 노드에서 동일한 IPVS 분산 설정 정보 확인
: 3곳의 목적지는 각각 서비스에 연동된 목적지 파드 3개이며, 전달 시 출발지 IP는 마스커레이딩 변환 처리


: ipset list 를 사용하지 않을 경우 6개의 iptables 규칙이 필요하지만, ipset 사용 시 1개의 규칙으로 가능
▶ IPVS 정보 확인 및 서비스 접속 확인


: 부하분산 접속 확인
▶ IPVS CLusterIP
▶ IPVS NodePort
▶ IPVS LoadBalancer by MetalLB
LoxiLB
- LoxiLB는 eBPF를 핵심 엔진으로 사용하고 Go Language를 기반으로 개발된 클라우드 네이티브 로드 밸런서입니다.
- Kubernetes 기반의 워크로드를 위한 오픈 소스 기반 external 로드 밸런서 솔루션 입니다.
- LoxiLB는 초저지연 포워딩과 프로그래머빌러티가 가능한 Kubernetes 표준 기반의 로드 밸런싱 서비스를 제공합니다.
- 배포, 부트스트래핑, 구성, 프로비저닝, 확장, 업그레이드, 마이그레이션, 라우팅, 모니터링 및 리소스 관리와 같은 외부 로드 밸런서 관리 작업을 자동화 합니다.
- 기본적으로 온프레미스 및 에지 클라우드 환경을 지원하도록 설계되었지만 모든 클라우드 환경에서 동일하게 실행 가능합니다.

1. LoxiLB
- eBPF & SmartNIC 컴파일러 기술을 활용한 클라우드 네이티브 네트워킹 최적화 및 자동화
- 소프트웨어 설치만으로 서버 환경에 맞게 네트워킹 최적화 (맞춤형 오프로딩) - eBPF & SmartNIC 프로그래머빌러티를 활용한 5G 요구기술 개발
2. eBPF란?
- eBPF(extended Berkeley Packet Filter)는 Kernal Level에서 Bytecode에 따라 동작하는 경량화된 VM(Virtual Machine)이고, eXpress Data Path(XDP)는 eBPF 프로그램을 Driver space로 로드하여 커널의 고성능 패킷 처리를 제공할 수 있는 기술이다.
- LoxiLB는 eBPF/XDP와 SmartNIC 레벨까지의 네트워크 오프로딩을 통해 초고속 패킷 처리를 제공 합니다.
3. LoxiLB 동작 모드
- Standalone Mode : 어플라이언스 형태의 단일 모드, CLI/API를 활용한 로드밸런서 설정 관리
- k8s Mode : k8s CCM을 통한 연동 모드, k8s CCM과 NetworkPolicy Spec을 통한 로드밸런서 설정 관리
▶ k3s 소개
- rancher 회사에서 IoT 및 edge computing 디바이스 위에서도 동작할 수 있도록 만들어진 경량 k8s 입니다
- 장점 : 설치가 쉽다, 가볍다(etcd, cloud manager 등 무거운 컴포넌트 제거), 학습용 및 테스트 시 필요한 기능들은 대부분 탑재
- 아키텍처(Single-server Setup with an Embedded DB) : 1대 K3s 서버(경량 DB = SQLite), 필요한 만큼의 k3s Agents (워커 노드들)
▶ 실습 구성
- VM(가상 머신) 정보 : 워커 노드는 2대로 구성
- VM에 vNIC은 2개를 사용 : vNIC1 용도(다른 PC에서 VM 인입 접근 시, VM에서 외부 통신 시), vNIC2 용도(k8s 관련 제어 및 Pod 간 통신 등)
- vNIC2 네트워크 대역은 수정해서 사용 가능 : 혹시 Home PC가 사용중인 RealNIC 대역에 192.168.200.0/24 대역과 겹치지 않아야 함
[ Netfilter ]
: Network Packet Filtering Framework로 Linux Kernel Space에 위치하여 모든 오고 가는 패킷의 생명주기를 모니터링하고 통제 및 조작할 수 있는 기능 제공
[ Netfilter Hook point ] - Application을 개발하면 패킷 필터링을 할 수 있도록 해줌
1. NF_IP_PRE_ROUTING : 외부에서 온 Packet이 Linux Kernel의 Network Stack을 통과하기 전에 발생하는 Hook
2. NF_IP_LOCAL_IN : Packet이 Routing 된 후 목적지가 자신일 경우, Packet을 Process에 전달하기 전에 발생
3. NF_IP_FORWARD : Packet이 Routing 된 후 목적지가 자신이 아닐 경우, Packet을 다른 곳으로 Forwarding
4. NF_IP_LOCAL_OUT : Packet이 Process에 나와 Network Stack을 통과하기 전 발생
5. NF_IP_POST_ROUTING : Packet이 Network Stack을 통과한 후 밖으로 보내기 전 발생
[ iptables Tables ] - 5가지 제공
1. filter Table : packet을 drop할지 전달할지 결정
2. NAT Table : Packet NAT(Network Address Translation)을 위한 table. packet의 source/destination address를 변경
3. Mangle Table : Packet의 IP header를 바꿈. Packet의 TTL 변경, Marking 하여 다른 iptables의 Table이나 Network tool에서 packet을 구분할 수 있도록 함
4. Raw Table : Netfilter Framework는 Hook 뿐만 아니라 Connection Tracking 기능을 제공한다. 이전에 도착한 Packet들을 바탕으로 방금 도착한 Packet의 Connection을 추적한다.
5. Security Table : SELinux에서 Packet을 어떻게 처리할지 결정하기 위함이다.
[ kube-proxy란? ]
: Kubernetes cluster를 구성하는 모듈 중 하나로 모든 Worker Node에 배포되어 동작하며 kube-proxy는 Pod의 Networking을 관리한다.
: Kubernetes 네트워크를 설정하기 위해 Service Object를 생성했다면 kubernetes Cluster에서는 해당 Service Object에 설정된 것을 반영해서 네트워킹을 관리하기 위해 kube-proxy 모듈을 사용한다.
: network proxy, load balancer 역할을 수행하고 있다.
[ kube-proxy Mode 종류 ]
1. userspace mode : kubernetes 개발 초기 최초로 default mode로 사용
> userspace mode에서 패킷 Rule 설정 및 로드밸런싱을 포함한 대부분의 Networking 작업이 kube-proxy에 의해서 직접 수행된다.
> (단점) Process에서 계산을 위한 CPU , I/O 작업을 위한 disk, memory 등 필요할 때 Kernel에 서비스를 요청하는 구조로 동작을 위해 User Space에서 Kernel에 액세스 해야하기 때문에 네트워킹 속도가 저하되는 문제점이 있다.
2. iptables mode : userspace의 단점을 보완하고 kubernetes 1.19.2 version 기준 현재 default mode로 제공
> kube-proxy가 client로 부터 트래픽을 받지 않고 iptables만 관리한다. iptables를 통해 linux kernel의 Netfilter를 설정하고 client로부터 오는 request는 Netfilter를 거쳐서 직접 pod로 전달된다. ( 모든 Networking 작업을 iptables/Netfilter로 한다)
> (단점) iptables 규칙은 처음 선택한 Pod가 응답하지 않을 경우 다른 Pod를 자동으로 재시도하는 메커니즘이 없다.
3. IPVS mode : iptables mode 보다 높은 성능을 보여주고 있다
> Kubernetes cluster에 생성/삭제되는 Service Object와 Pod를 파악하고 파악한 정보에 따라 IPVS 규칙을 설정한다. client로 부터 오는 request는 Netfilter 통해 IPVS 전달되어 IPVS가 모든 Networking 작업을 처리해서 request를 pod로 전달한다. ( IPVS의 Tunneling의 경우 NAT로 동작된다 )
공통점 : Netfilter Framework 사용